Chapter 6 Muraro human pancreas (CEL-seq)
6.1 Introduction
This performs an analysis of the Muraro et al. (2016) CEL-seq dataset, consisting of human pancreas cells from various donors.
6.2 Data loading
Converting back to Ensembl identifiers.
library(AnnotationHub)
edb <- AnnotationHub()[["AH73881"]]
gene.symb <- sub("__chr.*$", "", rownames(sce.muraro))
gene.ids <- mapIds(edb, keys=gene.symb,
keytype="SYMBOL", column="GENEID")
# Removing duplicated genes or genes without Ensembl IDs.
keep <- !is.na(gene.ids) & !duplicated(gene.ids)
sce.muraro <- sce.muraro[keep,]
rownames(sce.muraro) <- gene.ids[keep]6.3 Quality control
This dataset lacks mitochondrial genes so we will do without. For the one batch that seems to have a high proportion of low-quality cells, we compute an appropriate filter threshold using a shared median and MAD from the other batches (Figure 6.1).
library(scater)
stats <- perCellQCMetrics(sce.muraro)
qc <- quickPerCellQC(stats, percent_subsets="altexps_ERCC_percent",
batch=sce.muraro$donor, subset=sce.muraro$donor!="D28")
sce.muraro <- sce.muraro[,!qc$discard]colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$discard <- qc$discard
gridExtra::grid.arrange(
plotColData(unfiltered, x="donor", y="sum", colour_by="discard") +
scale_y_log10() + ggtitle("Total count"),
plotColData(unfiltered, x="donor", y="detected", colour_by="discard") +
scale_y_log10() + ggtitle("Detected features"),
plotColData(unfiltered, x="donor", y="altexps_ERCC_percent",
colour_by="discard") + ggtitle("ERCC percent"),
ncol=2
)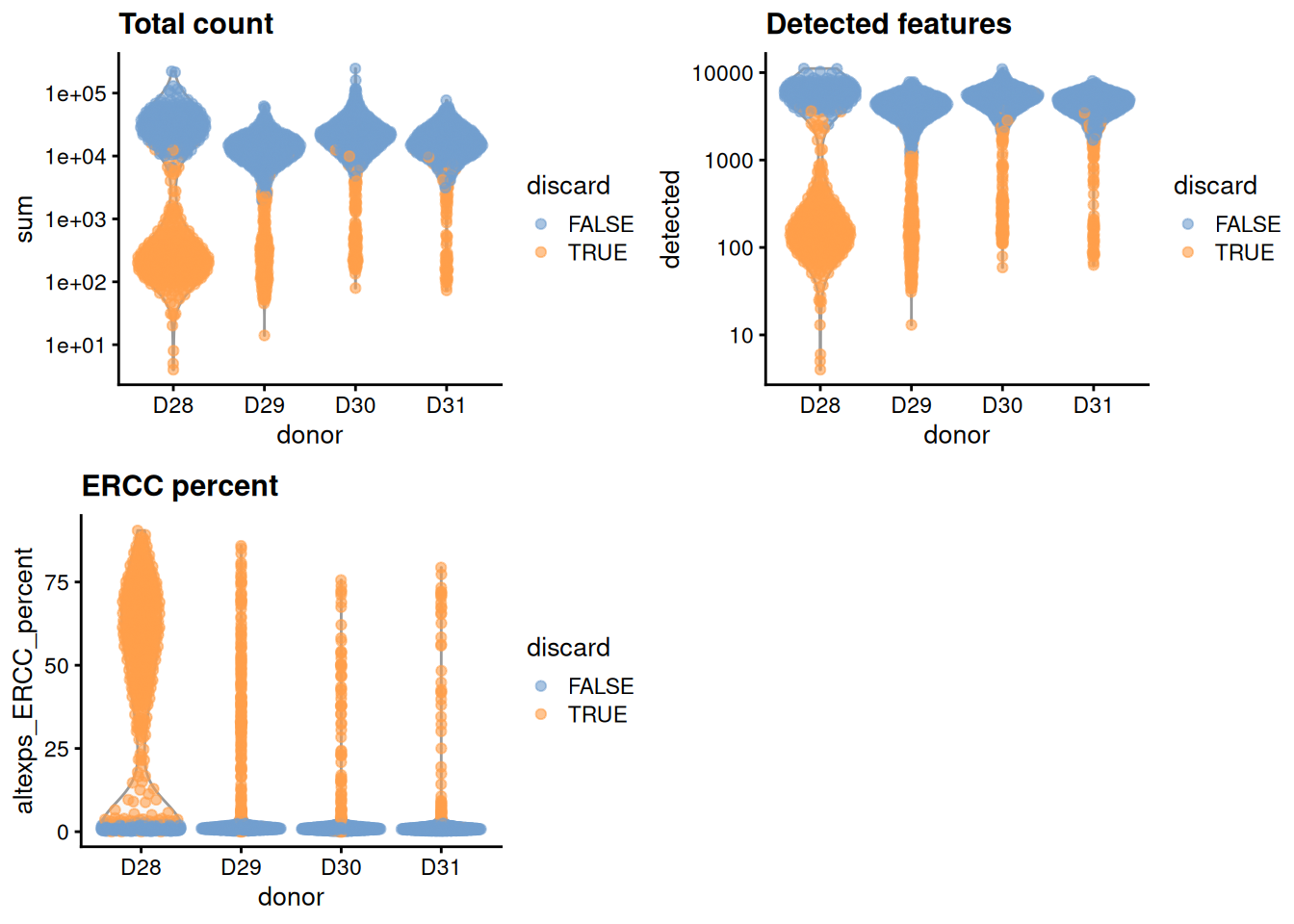
Figure 6.1: Distribution of each QC metric across cells from each donor in the Muraro pancreas dataset. Each point represents a cell and is colored according to whether that cell was discarded.
We have a look at the causes of removal:
## low_lib_size low_n_features high_altexps_ERCC_percent
## 663 700 738
## discard
## 7736.4 Normalization
library(scran)
set.seed(1000)
clusters <- quickCluster(sce.muraro)
sce.muraro <- computeSumFactors(sce.muraro, clusters=clusters)
sce.muraro <- logNormCounts(sce.muraro)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.088 0.541 0.821 1.000 1.211 13.987plot(librarySizeFactors(sce.muraro), sizeFactors(sce.muraro), pch=16,
xlab="Library size factors", ylab="Deconvolution factors", log="xy")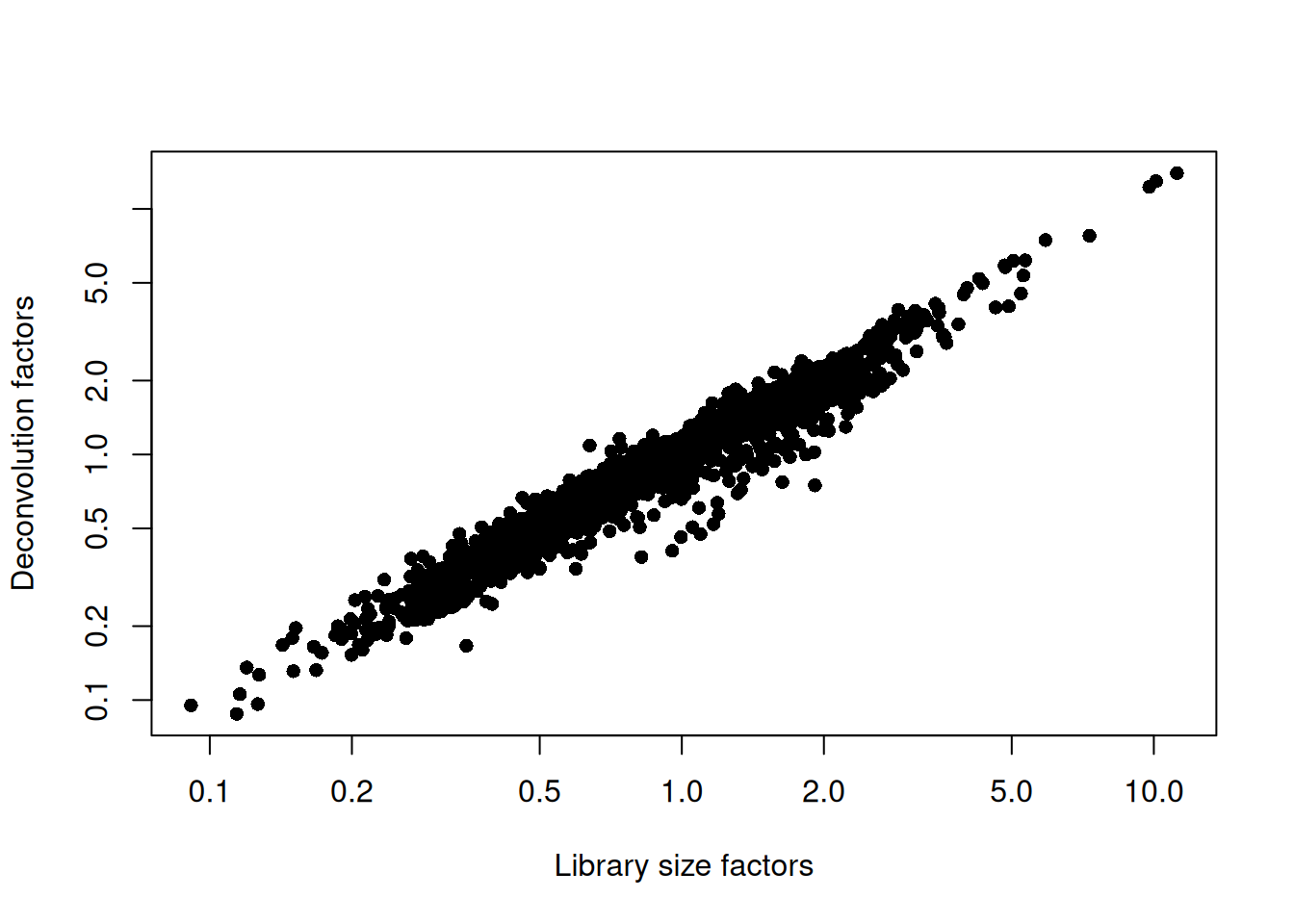
Figure 6.2: Relationship between the library size factors and the deconvolution size factors in the Muraro pancreas dataset.
6.5 Variance modelling
We block on a combined plate and donor factor.
block <- paste0(sce.muraro$plate, "_", sce.muraro$donor)
dec.muraro <- modelGeneVarWithSpikes(sce.muraro, "ERCC", block=block)
top.muraro <- getTopHVGs(dec.muraro, prop=0.1)par(mfrow=c(8,4))
blocked.stats <- dec.muraro$per.block
for (i in colnames(blocked.stats)) {
current <- blocked.stats[[i]]
plot(current$mean, current$total, main=i, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(current)
points(curfit$mean, curfit$var, col="red", pch=16)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)
}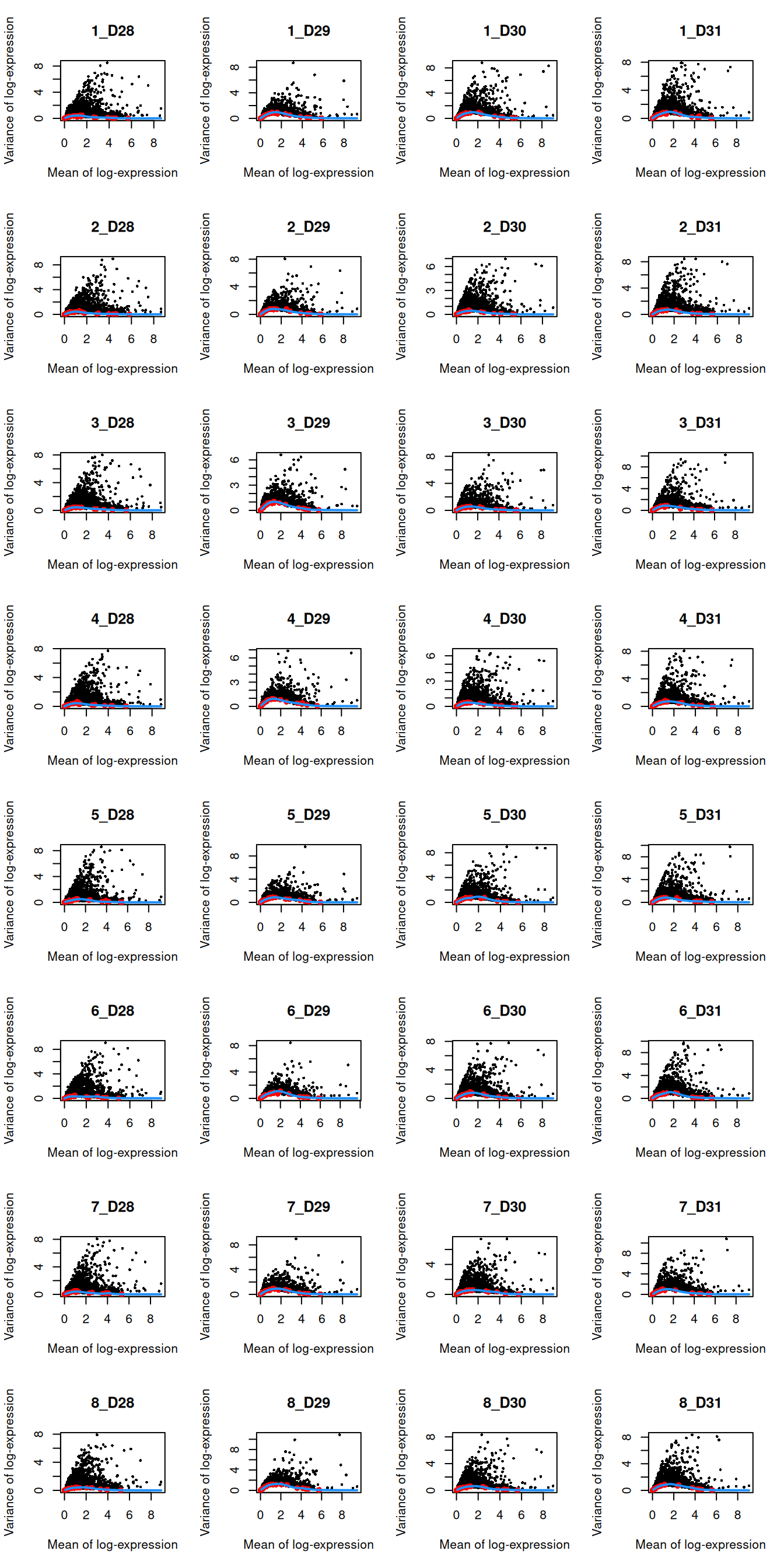
Figure 6.3: Per-gene variance as a function of the mean for the log-expression values in the Muraro pancreas dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to the spike-in transcripts (red) separately for each donor.
6.6 Data integration
library(batchelor)
set.seed(1001010)
merged.muraro <- fastMNN(sce.muraro, subset.row=top.muraro,
batch=sce.muraro$donor)We use the proportion of variance lost as a diagnostic measure:
## D28 D29 D30 D31
## [1,] 0.060847 0.024121 0.000000 0.00000
## [2,] 0.002646 0.003018 0.062421 0.00000
## [3,] 0.003449 0.002641 0.002598 0.081626.8 Clustering
snn.gr <- buildSNNGraph(merged.muraro, use.dimred="corrected")
colLabels(merged.muraro) <- factor(igraph::cluster_walktrap(snn.gr)$membership)tab <- table(Cluster=colLabels(merged.muraro), CellType=sce.muraro$label)
library(pheatmap)
pheatmap(log10(tab+10), color=viridis::viridis(100))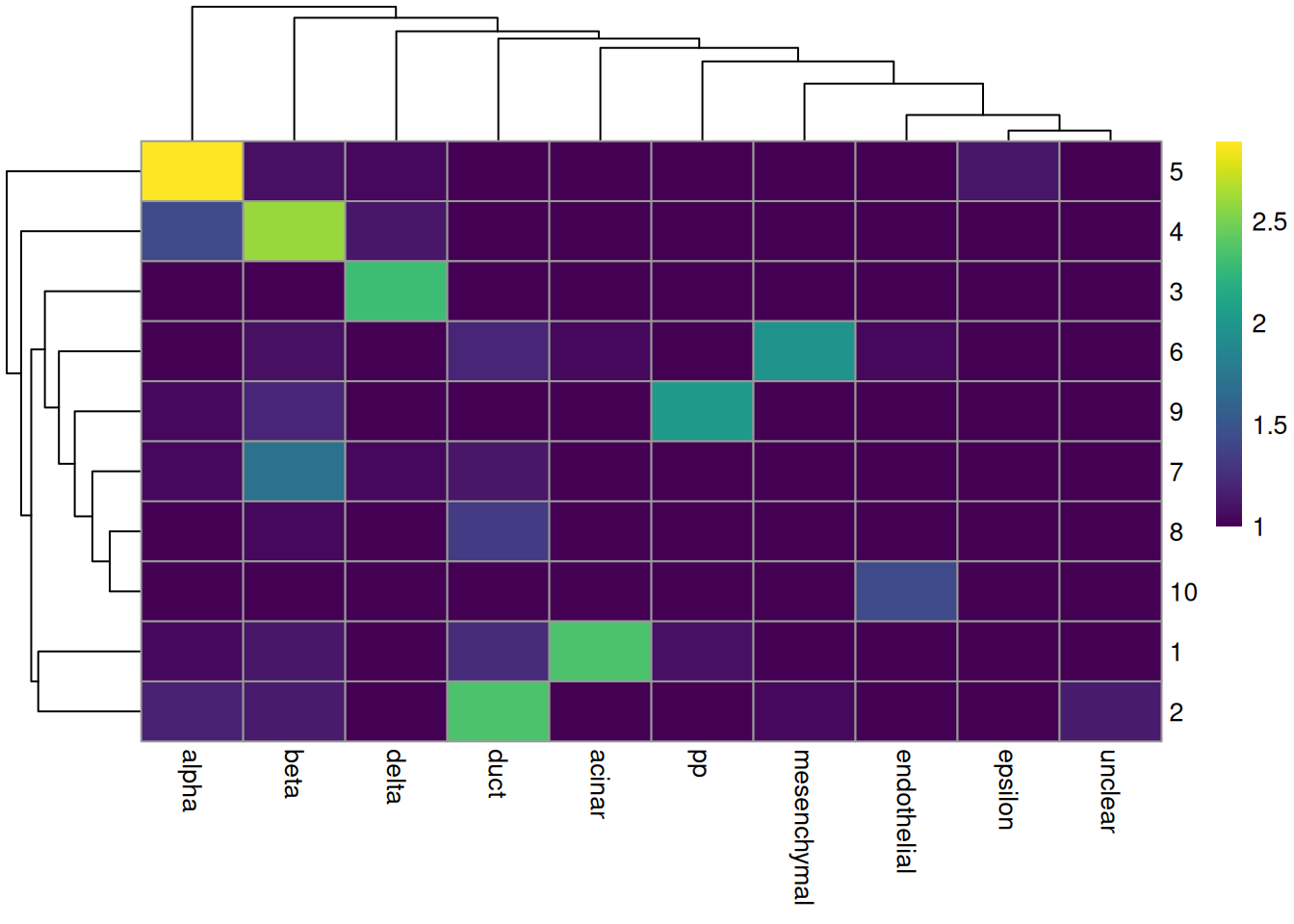
Figure 6.4: Heatmap of the frequency of cells from each cell type label in each cluster.
## Donor
## Cluster D28 D29 D30 D31
## 1 104 6 57 112
## 2 59 21 77 97
## 3 12 75 64 43
## 4 28 149 126 120
## 5 87 261 277 214
## 6 21 7 54 26
## 7 1 6 6 37
## 8 6 6 5 2
## 9 11 68 5 30
## 10 4 2 5 8gridExtra::grid.arrange(
plotTSNE(merged.muraro, colour_by="label"),
plotTSNE(merged.muraro, colour_by="batch"),
ncol=2
)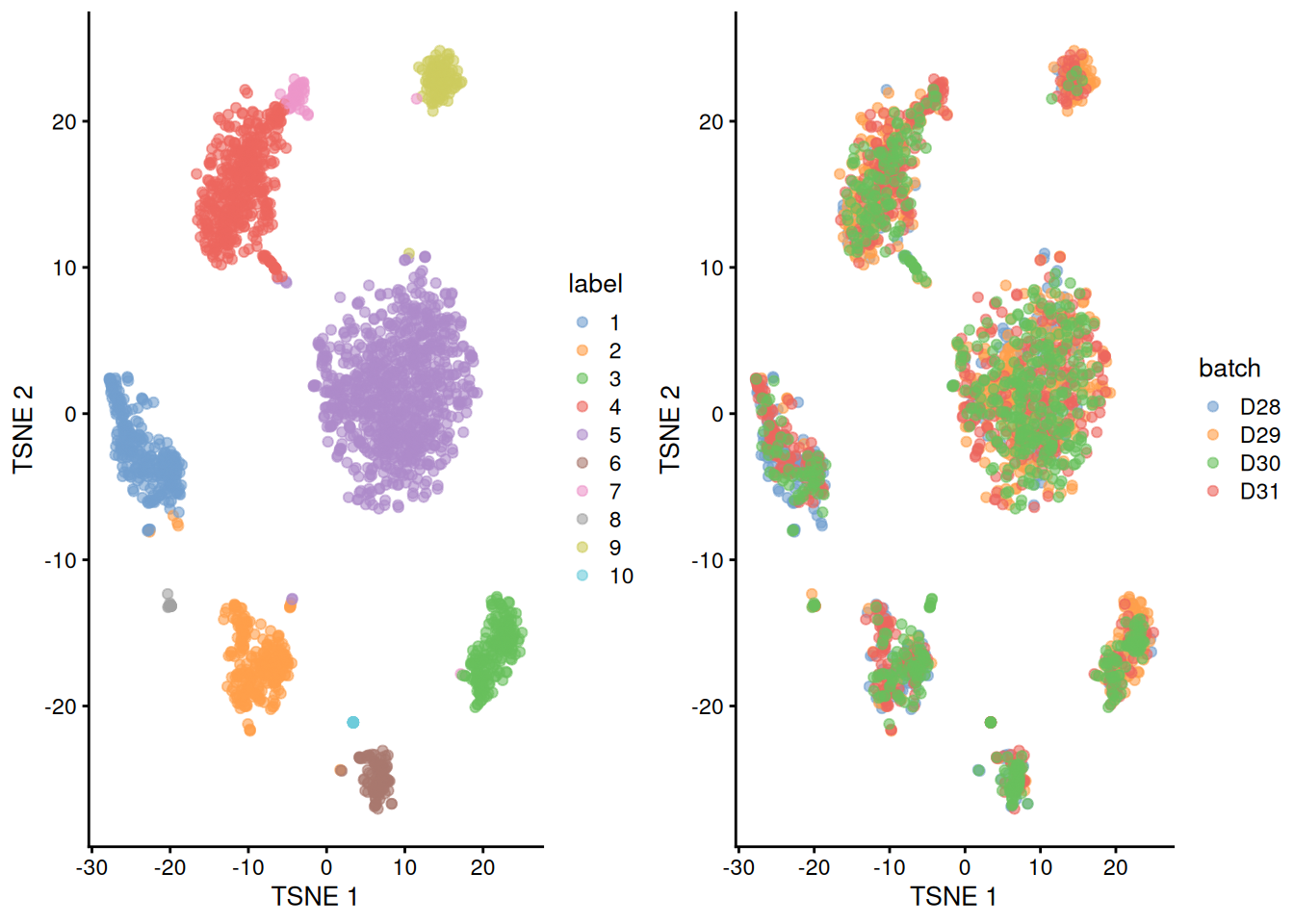
Figure 6.5: Obligatory \(t\)-SNE plots of the Muraro pancreas dataset. Each point represents a cell that is colored by cluster (left) or batch (right).
Session Info
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.1 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.20-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] pheatmap_1.0.12 batchelor_1.22.0
[3] scran_1.34.0 scater_1.34.0
[5] ggplot2_3.5.1 scuttle_1.16.0
[7] ensembldb_2.30.0 AnnotationFilter_1.30.0
[9] GenomicFeatures_1.58.0 AnnotationDbi_1.68.0
[11] AnnotationHub_3.14.0 BiocFileCache_2.14.0
[13] dbplyr_2.5.0 scRNAseq_2.19.1
[15] SingleCellExperiment_1.28.0 SummarizedExperiment_1.36.0
[17] Biobase_2.66.0 GenomicRanges_1.58.0
[19] GenomeInfoDb_1.42.0 IRanges_2.40.0
[21] S4Vectors_0.44.0 BiocGenerics_0.52.0
[23] MatrixGenerics_1.18.0 matrixStats_1.4.1
[25] BiocStyle_2.34.0 rebook_1.16.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_1.8.9
[3] CodeDepends_0.6.6 magrittr_2.0.3
[5] ggbeeswarm_0.7.2 gypsum_1.2.0
[7] farver_2.1.2 rmarkdown_2.28
[9] BiocIO_1.16.0 zlibbioc_1.52.0
[11] vctrs_0.6.5 DelayedMatrixStats_1.28.0
[13] memoise_2.0.1 Rsamtools_2.22.0
[15] RCurl_1.98-1.16 htmltools_0.5.8.1
[17] S4Arrays_1.6.0 curl_5.2.3
[19] BiocNeighbors_2.0.0 Rhdf5lib_1.28.0
[21] SparseArray_1.6.0 rhdf5_2.50.0
[23] sass_0.4.9 alabaster.base_1.6.0
[25] bslib_0.8.0 alabaster.sce_1.6.0
[27] httr2_1.0.5 cachem_1.1.0
[29] ResidualMatrix_1.16.0 GenomicAlignments_1.42.0
[31] igraph_2.1.1 mime_0.12
[33] lifecycle_1.0.4 pkgconfig_2.0.3
[35] rsvd_1.0.5 Matrix_1.7-1
[37] R6_2.5.1 fastmap_1.2.0
[39] GenomeInfoDbData_1.2.13 digest_0.6.37
[41] colorspace_2.1-1 dqrng_0.4.1
[43] irlba_2.3.5.1 ExperimentHub_2.14.0
[45] RSQLite_2.3.7 beachmat_2.22.0
[47] labeling_0.4.3 filelock_1.0.3
[49] fansi_1.0.6 httr_1.4.7
[51] abind_1.4-8 compiler_4.4.1
[53] bit64_4.5.2 withr_3.0.2
[55] BiocParallel_1.40.0 viridis_0.6.5
[57] DBI_1.2.3 highr_0.11
[59] HDF5Array_1.34.0 alabaster.ranges_1.6.0
[61] alabaster.schemas_1.6.0 rappdirs_0.3.3
[63] DelayedArray_0.32.0 bluster_1.16.0
[65] rjson_0.2.23 tools_4.4.1
[67] vipor_0.4.7 beeswarm_0.4.0
[69] glue_1.8.0 restfulr_0.0.15
[71] rhdf5filters_1.18.0 grid_4.4.1
[73] Rtsne_0.17 cluster_2.1.6
[75] generics_0.1.3 gtable_0.3.6
[77] metapod_1.14.0 BiocSingular_1.22.0
[79] ScaledMatrix_1.14.0 utf8_1.2.4
[81] XVector_0.46.0 ggrepel_0.9.6
[83] BiocVersion_3.20.0 pillar_1.9.0
[85] limma_3.62.0 dplyr_1.1.4
[87] lattice_0.22-6 rtracklayer_1.66.0
[89] bit_4.5.0 tidyselect_1.2.1
[91] locfit_1.5-9.10 Biostrings_2.74.0
[93] knitr_1.48 gridExtra_2.3
[95] bookdown_0.41 ProtGenerics_1.38.0
[97] edgeR_4.4.0 xfun_0.48
[99] statmod_1.5.0 UCSC.utils_1.2.0
[101] lazyeval_0.2.2 yaml_2.3.10
[103] evaluate_1.0.1 codetools_0.2-20
[105] tibble_3.2.1 alabaster.matrix_1.6.0
[107] BiocManager_1.30.25 graph_1.84.0
[109] cli_3.6.3 munsell_0.5.1
[111] jquerylib_0.1.4 Rcpp_1.0.13
[113] dir.expiry_1.14.0 png_0.1-8
[115] XML_3.99-0.17 parallel_4.4.1
[117] blob_1.2.4 sparseMatrixStats_1.18.0
[119] bitops_1.0-9 viridisLite_0.4.2
[121] alabaster.se_1.6.0 scales_1.3.0
[123] purrr_1.0.2 crayon_1.5.3
[125] rlang_1.1.4 cowplot_1.1.3
[127] KEGGREST_1.46.0 References
Muraro, M. J., G. Dharmadhikari, D. Grun, N. Groen, T. Dielen, E. Jansen, L. van Gurp, et al. 2016. “A Single-Cell Transcriptome Atlas of the Human Pancreas.” Cell Syst 3 (4): 385–94.